
Partnership management for
influencers
retail
brand-to-brand
affiliates
commerce content
ambassadors
creators
FinTech
SaaS
travel
impact.com makes high-value partnerships possible by understanding every stage of the customer journey












Gain more visibility, build authentic connections, and grow revenue for your brand

Influencer
Attract higher-value customers by building relationships through creators and influencers. With impact.com / creator, you can customize influencer contracts, and payment models to make the most of brand and performance campaigns.

Affiliate
Take less risk, ditch manual processes, and drive higher ROI with a diverse affiliate marketplace. You can build bespoke affiliate partnerships, customize contracts, and measure true partner value with impact.com.

B2B SaaS
Referral partnerships are the most cost-effective way to generate more leads, grow your subscription base and increase revenue. No other channel allows for a pay-for-performance model that truly creates both a better user experience and a better business outcome.

Mobile
Grow in-app sales with native integrations, and pay partners for post-install conversion events like sales, travel bookings, or new subscriptions. Drive partner traffic into your app and connect with new, mobile-first partners.
Discover new brands to grow your content programs, and make data-driven decisions so you can scale faster
Creators
Monetize your content and build long-term brand partnerships that help grow your audience. Plus, show your true value through data, and facilitate contract and payment negotiations without leaving the platform.
Affiliates
Connect with brands that align with your readership and audience while showcasing high-converting products in your content. Plus, understand the true value brands bring through real-time reporting, and optimize content for greater conversions.

Premium publishers
As the publishing landscape becomes more competitive, it’s critical to focus on content that converts. With impact.com, you get centralized data from over 200 channels and networks to drive true value from partnerships.
Mobile apps
Connect directly with hundreds of leaders of the mobile economy. Refer traffic from your mobile properties and activate a new revenue stream.





Creator
Build high-value creator partnerships at scale
With impact.com / creator, you can discover influencer and creator partners that align with your brand, opening up a world of exciting collaborative opportunities. impact.com’s creator solution brings together like-minded brands, creators, and agencies, enabling effortless discovery for a perfect match. Our best in class performance tracking and reporting allows you to optimize top-performing partnerships to grow your audience and revenue.
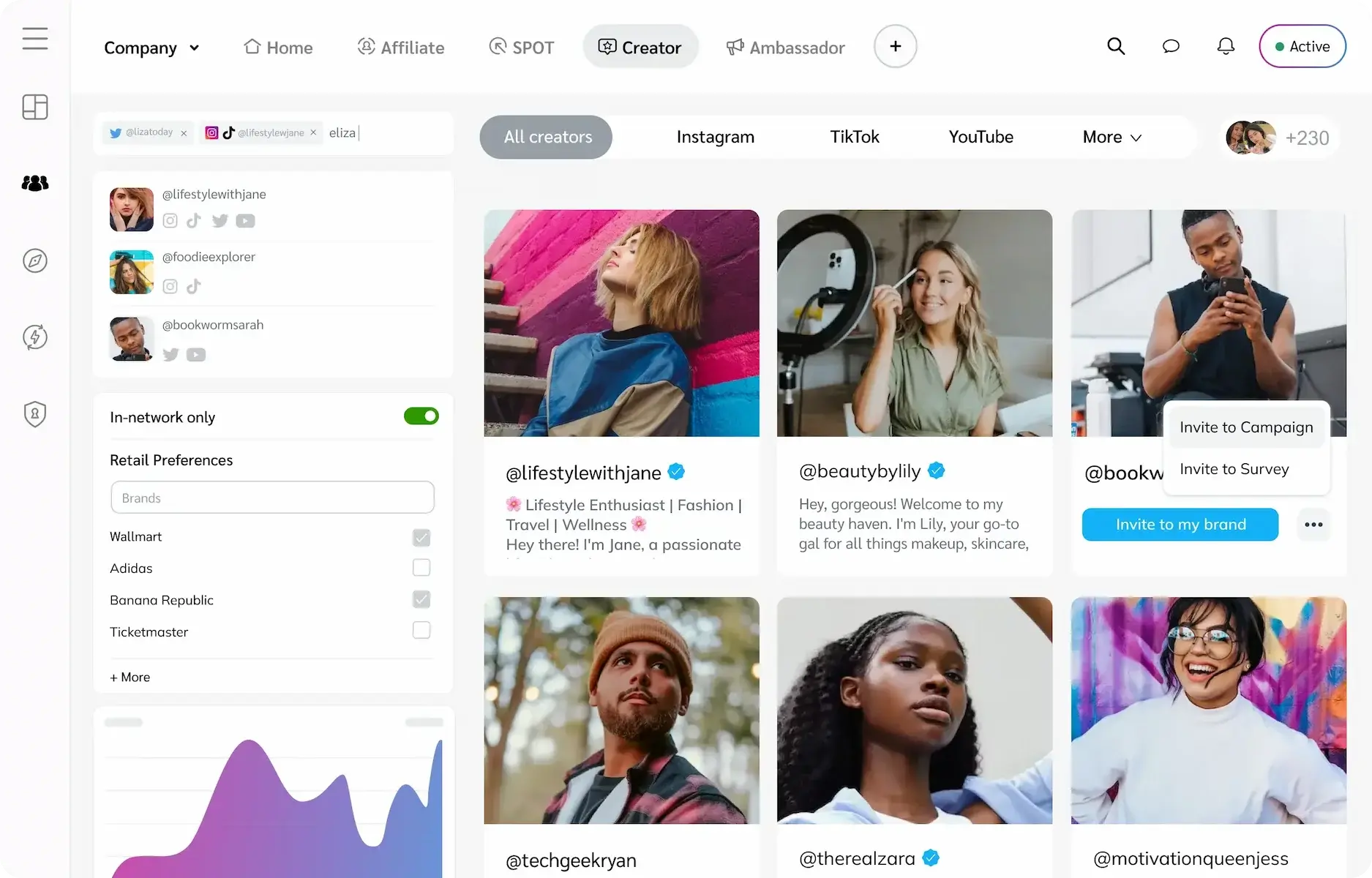
Affiliate
One platform to manage a complex universe of partnerships
Take less risk, ditch manual processes, and drive higher ROI with a diverse affiliate marketplace. You can build bespoke affiliate partnerships, customize contracts, and measure true partner value with impact.com. Affiliates can find thousands of brands in our Marketplace to partner with and monetize their content.
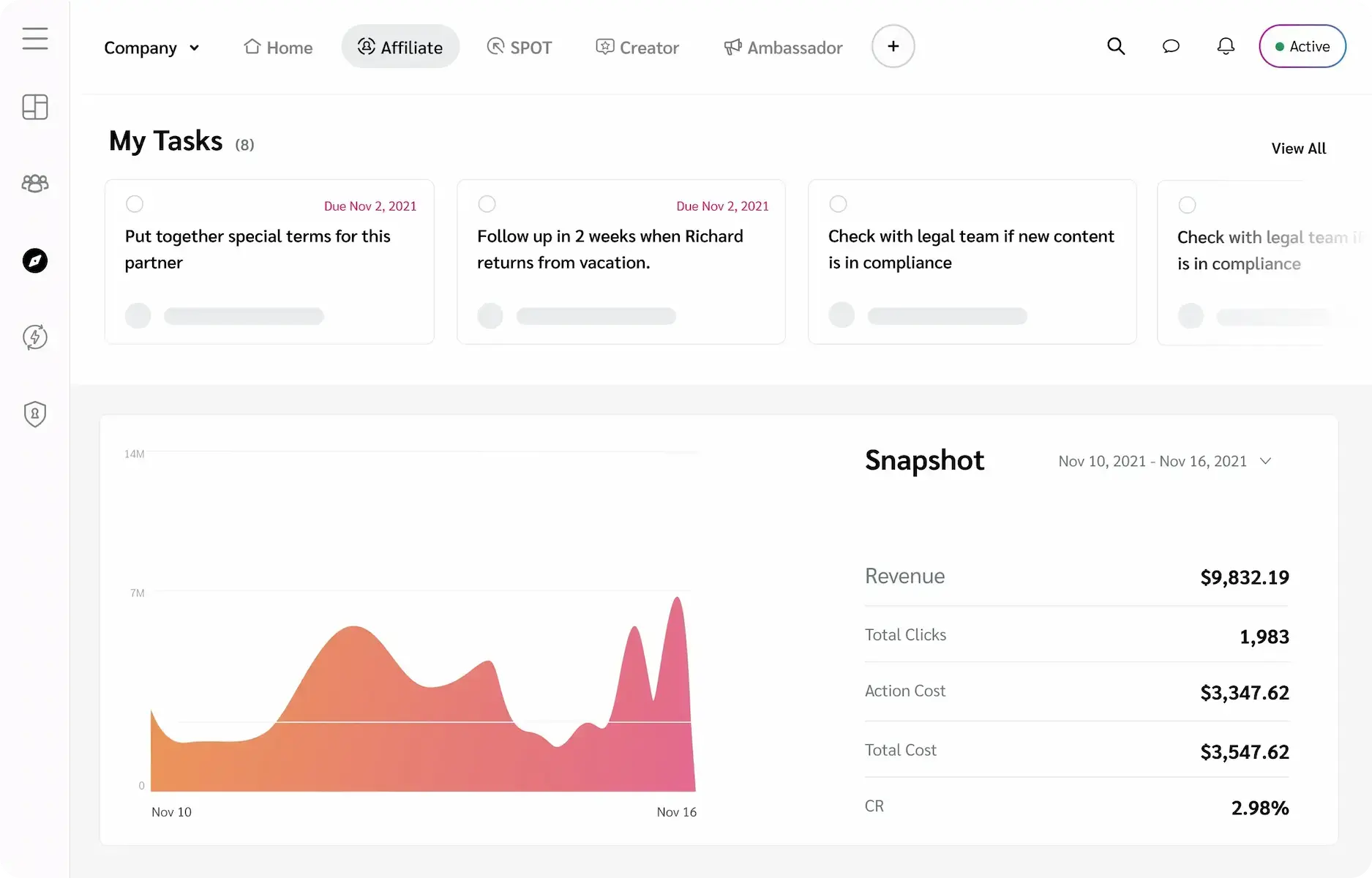
Premium publishers
The most powerful tools for modern publishers
Trusted by thousands of premium publishers globally across every major vertical: News, lifestyle, tech, fashion, parenting, travel, and more! The only full-stack technology solution that keeps publishers competitive in an ecosystem that is constantly evolving. Our publishers are equipped with cutting-edge tools to jumpstart, grow, and scale commerce content programs.
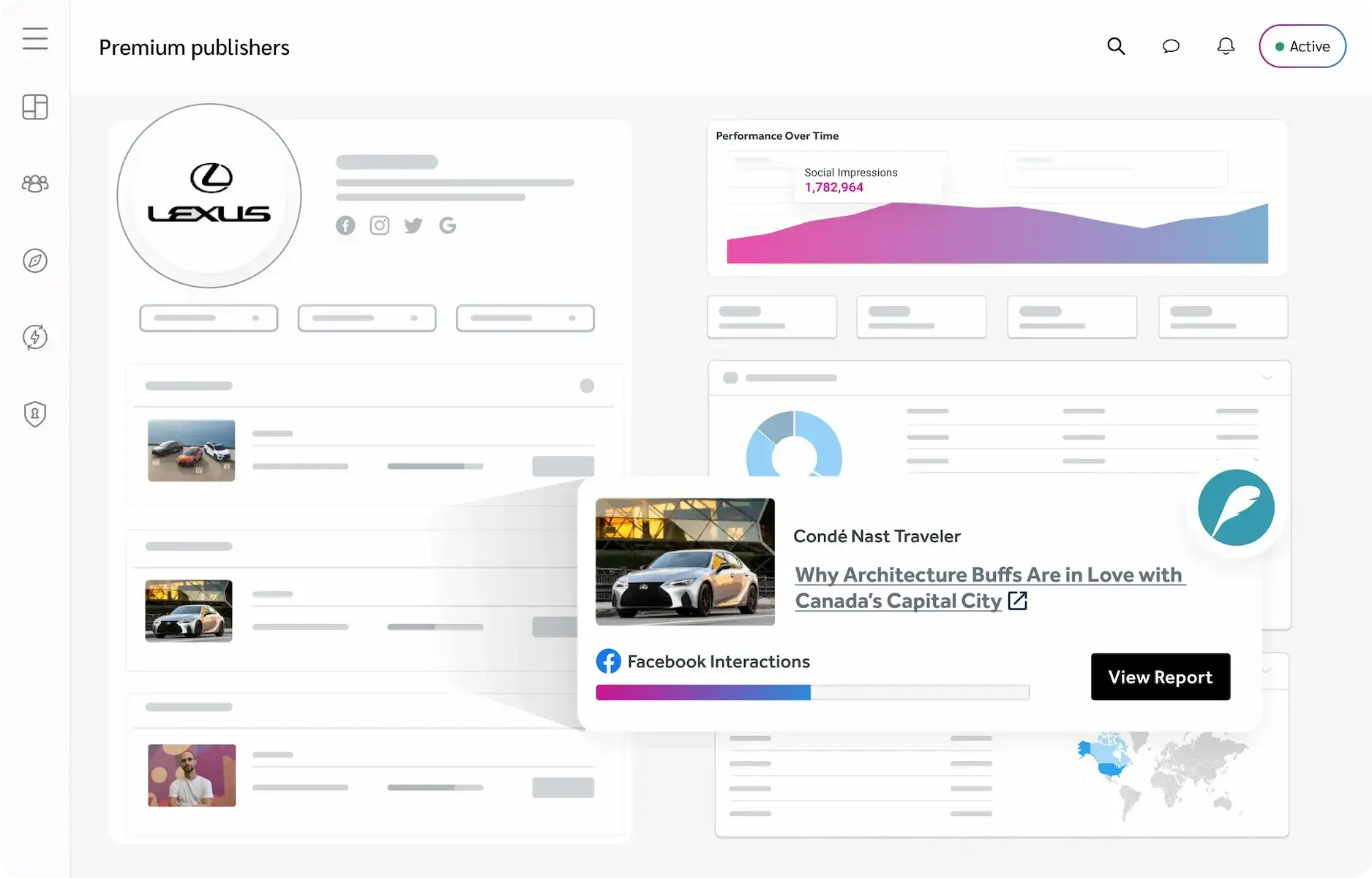
Marketplace
Find the right partners through our marketplace
Discover thousands of future revenue-generating partnerships, contract and begin working together directly through a cost-per-action model. Publishers can apply to work with their favorite brands, then monetize their content by driving traffic and conversions for their partners.

Tech integrations
Integrate with impact.com tech partners
Drive revenue and unlock new channels of growth with our e-commerce platform integrations. The impact.com app offers an all-in-one solution to guide you in your journey through influencer and affiliate marketing. Drive revenue and unlock new revenue streams with our e-commerce platform integrations with companies like Shopify, BigCommerce, Magento, Hubspot, and more.

Take your partnership program to the next level
Find out how impact.com’s partnership management platform can help you effectively orchestrate the entire partner lifecycle for sustained growth.
Request a demo
impact.com partnership management platform
Manages, protects, and optimizes all of your organization’s different partnerships. Learn more about how we can help you scale faster.
Discover & Recruit
Discover a limitless number of global partners—and add them to your partnership program with ease. Save time with powerful discovery and recruitment automation.
Contract & Pay
Choose your business outcomes, then reward the partners that drive them.
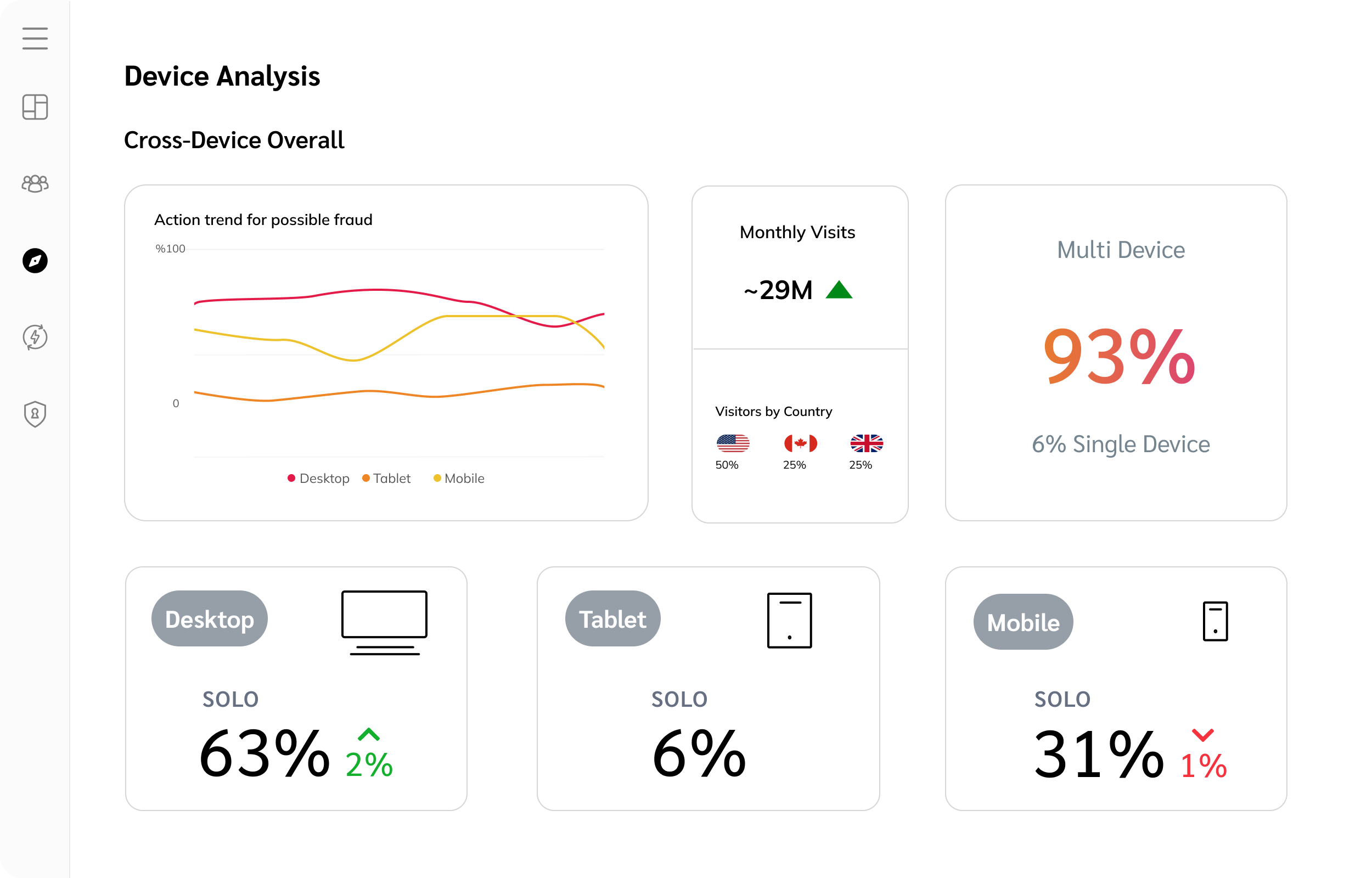
Track
Track the traffic partners drive on all your properties, across any device.
Engage
Proactive messaging and automated workflows make sure partners stay informed, productive, and on-brand.
Protect & Monitor
Fortify your partnerships with full-stack protection across the entire consumer journey. Automate the daily monitoring and remediation of issues that could result in partner non-compliance. Expose affiliate fraud, influencer fraud, and traffic abnormalities wherever they corrupt your conversion paths. Cut out invalid traffic and reinvest spend in high-quality partnerships.
Optimize
Continually optimize your partnerships for growth and efficiency.
Creator platform certification!
Run your creator campaigns from A–Z in this free certification for brands
We also recommend

Blog
The recession-proof influencer: How to thrive when marketing spend dries up

Blog
How much do influencers charge per post in 2024?

Blog
6 questions to consider when determining your content creator rates